1.为什么需要日志收集
当我们的网站规模大到一定程度时我们的服务分散在不同的主机上,当网站发生异常时我们通常通过这些服务的日志来排查系统故障,由于主机众多日志分散在不同的主机上,导致我们分析日志效率太低,日志收集系统可以实现将所有不同主机的上的日志汇聚到一个系统中,方便我们查看,分析。
2.开源软件选型
市面上有各种日志收集系统,通过多个开瑞软件整合来完成日志收集分析,大概包括si个部分:收集 -> 分析 -> 存储 -> 后台
做收集的有Apache的 Flume, Facebook的 Scribe,Elasic 的 Firebeat,Logstash
做分析,Logstash可以,别的暂时没有研究,还用不到
做存储的有 Elasticsearch,Hdfs(Hadoop , Storm) 等
做后台的有 kibana,grafana
用Hdfs的这种基本是做日志的大数据分析的,比较重,不太适合我们,Eliastic 有一套完整的日志方案就是
通常说的 Elk(Elasticsearch + Logstash + kibana), Logstash比较大,一般用他来做日志的分析格式化(二次处理),日志收集用 Firebeat, Flume也不错,不过需要装java环境,Friebeat 用go写的,对环境每依赖可以直接运行,而且很轻量大概 3M 多,这对部署实施时很有利。
Eliasticsearch 搜索的高效就不用说了,存时序数据也经常用它,对这个本身也有过一定了解
Kibana 用来做日志查看分析,跟Elasticsearch 配合起来使用,可以通过从es里搜索出来的数据做可视化展示,Dashboard数据监控面板
所以最后选择通过 Filebeat + Elasitcsearch + Kibana 来实现我们的日志收集系统(Logstash 可选)
目前Kibana稳定版在 4.4 ,但是要依赖 Elasticsearch 2 以上,
以前用过 Elasticsearch 1.7 的,所以选了 Elasticsearch 1.7 + Kibana 4.1
3.安装部署
centos 6.x 环境下
3.1 在日志所在服务器上安装Filebeat
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch将以下内容
[beats]
name=Elastic Beats Repository
baseurl=https://packages.elastic.co/beats/yum/el/$basearch
enabled=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
gpgcheck=1保存为 /etc/yum.repos.d/beat.repo 文件
开始安装
yum -y install filebeat
chkconfig --add filebeat启动命令
/etc/init.d/filebeat start
3.2 在日志服务器安装 Elasticsearch
mkdir -p ~/download && cd ~/download
wget -c https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.zip
unzip elasticsearch-1.7.2.zip
mv elasticsearch-1.7.2 /usr/local/elasticsearch启动命令
cd /usr/local/elasticsearch/bin
./elasticsearch -d3.3 在日志服务器安装 Kibana
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat > /etc/yum.repos.d/kibana.repo
[kibana-4.1]
name=Kibana repository for 4.1.x packages
baseurl=http://packages.elastic.co/kibana/4.1/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
yum install kibana
chkconfig --add kibana启动命令
/etc/init.d/kibana start4.使用方法
假如我们有一台 web 服务器, 上面跑了nginx + php-fpm,我们要收集php-fpm的 错误日志和慢日志
4.1配置 filebeat
filebeat:
prospectors:
-
document_type: "php-fpm"
paths:
- /var/log/php/php-fpm.log
-
document_type: "php-fpm.slow"
paths:
- /var/log/php/slow.log
multiline:
pattern: '^[[:space:]]'
negate: true
match: after
output:
elasticsearch:
hosts: ["192.168.1.88:9200"]
shipper:
tags: ["web"]
上面的配置表示从 /var/log/server/php/php-fpm.log, /var/log/server/php/cloud.slow.log 这两个位置收集日志,
其中由于 slow 日志存在多行的做为一条记录的情况,filebeat 通过三个配置来将多行转为一行, pattern, negate, match, 上面的配置表示,如果不是以空白开头的行将被拼接到上一行的后面,
pattern 遵循golang的正则语法
output 指令中指定将日志输出到 elasticsearch,并添加了服务所在ip 和端口,可以添加多台,还能支持负均衡
shipper 中可以指定一些tag,方便后面在 kibana 中筛选数据
好了,重启filebeat就可以了, /etc/init.d/filebeat restart
4.2 配置Elasticsearch
确保 Elasticsearch 已经启动
4.3 配置kibana
安装 filebeat 的示例仪表盘等
mkdir -p ~/download && cd ~/download
curl -L -O http://download.elastic.co/beats/dashboards/beats-dashboards-1.3.1.zip
unzip beats-dashboards-1.3.1.zip
cd beats-dashboards-1.3.1/
./load.sh默认情况下,脚本假设在127.0.0.1:9200上运行Elasticsearch。 使用-url选项指定其他位置。 例如:./load.sh -url http://192.168.1.88:9200 。
kibana中需要配置 elasticsearch 的地址和端口,现在两个服务都是在同一台上,配置默认是 localhost:9200,所以也不用改
4.4 打开kibana
kibana 启动后默认 端口是 5601 , 从浏览器打开 http://192.168.1.88:5601
kibana 会加载一个 5m的js ,所以要先耐心等待
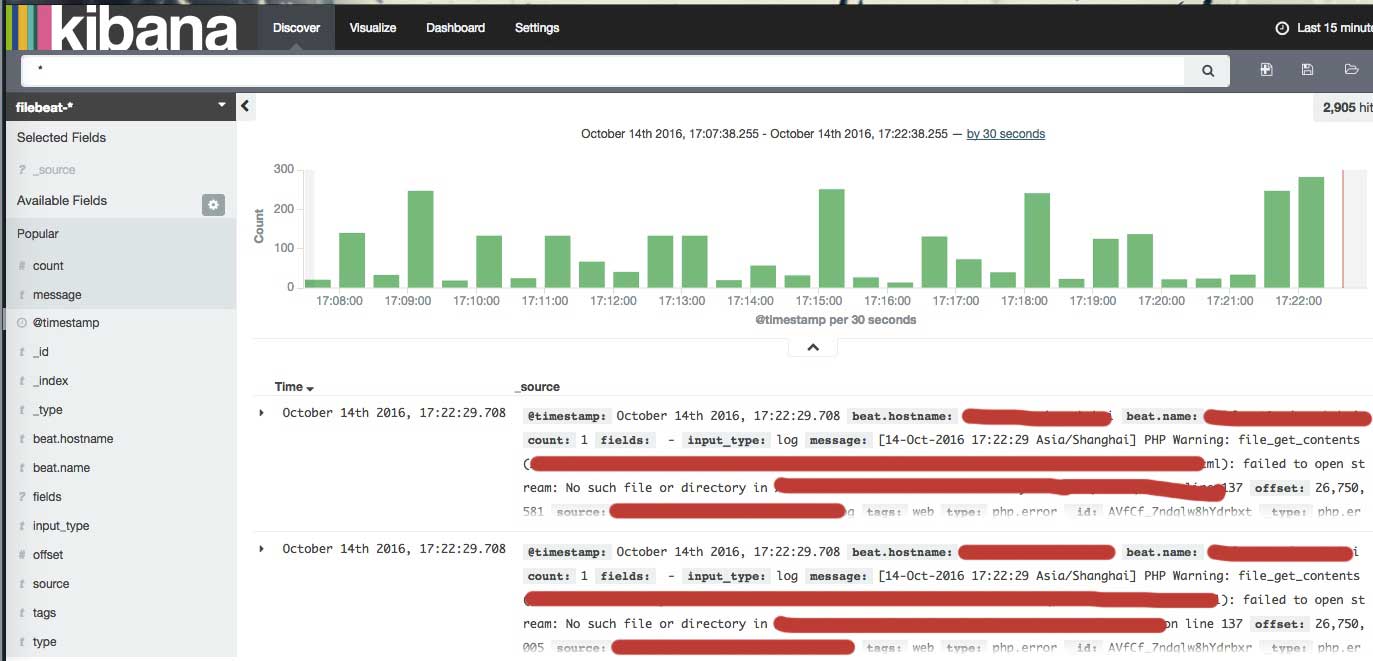
打开后界面是这样的
改成 filebeat-*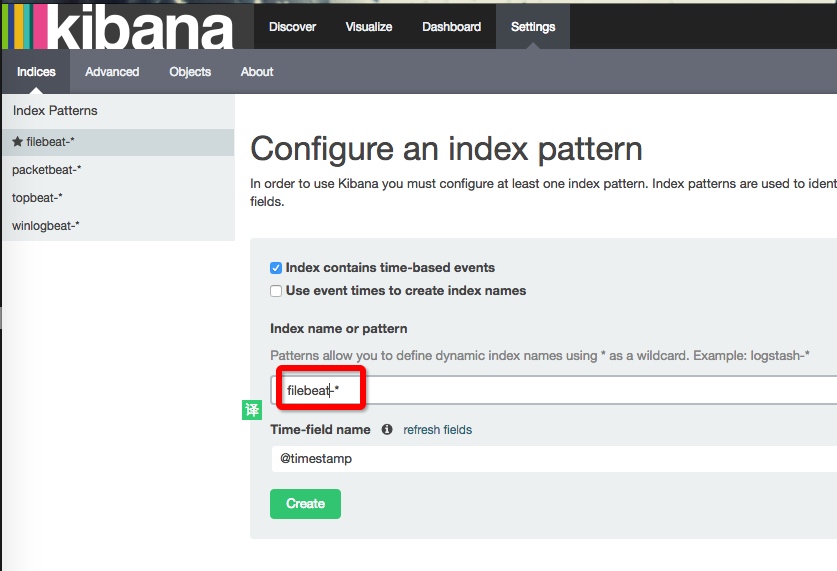
点 create ,然后点 Discover, 进来后如果日志中有数据,我们应该可以看到类似下面的界面

区域说明
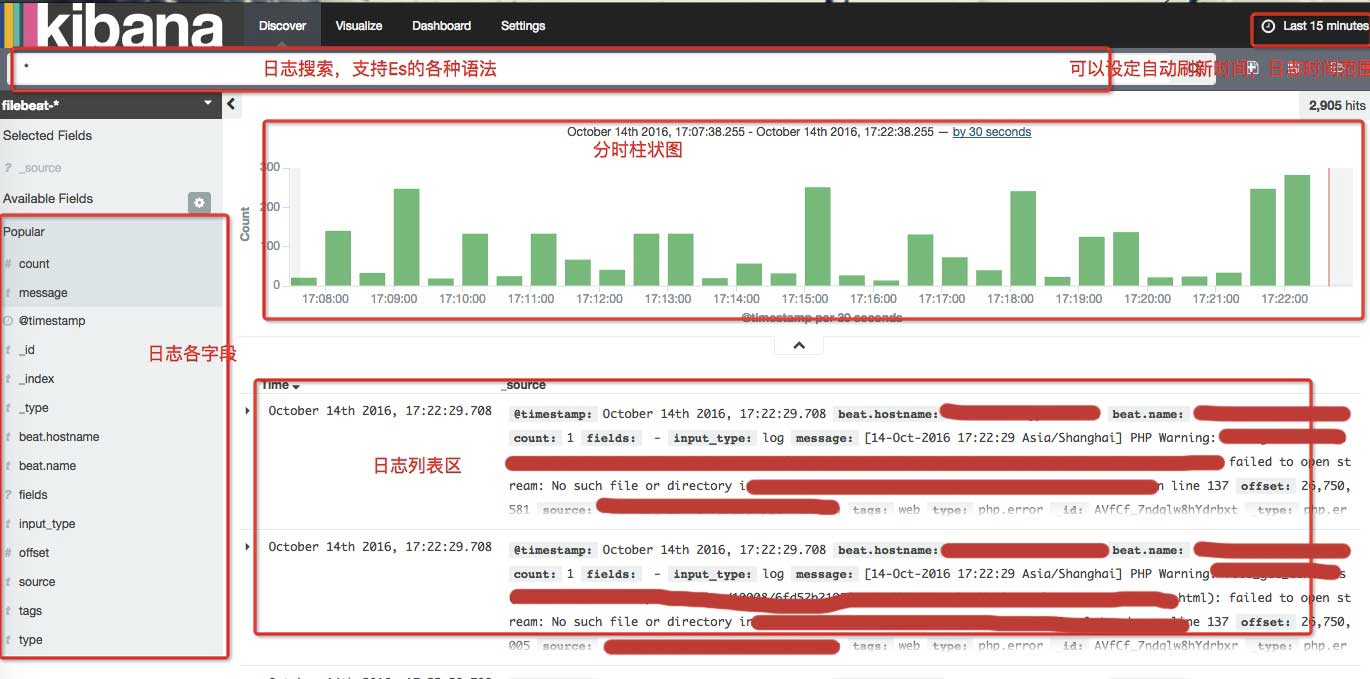
点 type 可以看到我们在filebeat 中指定的日志名称
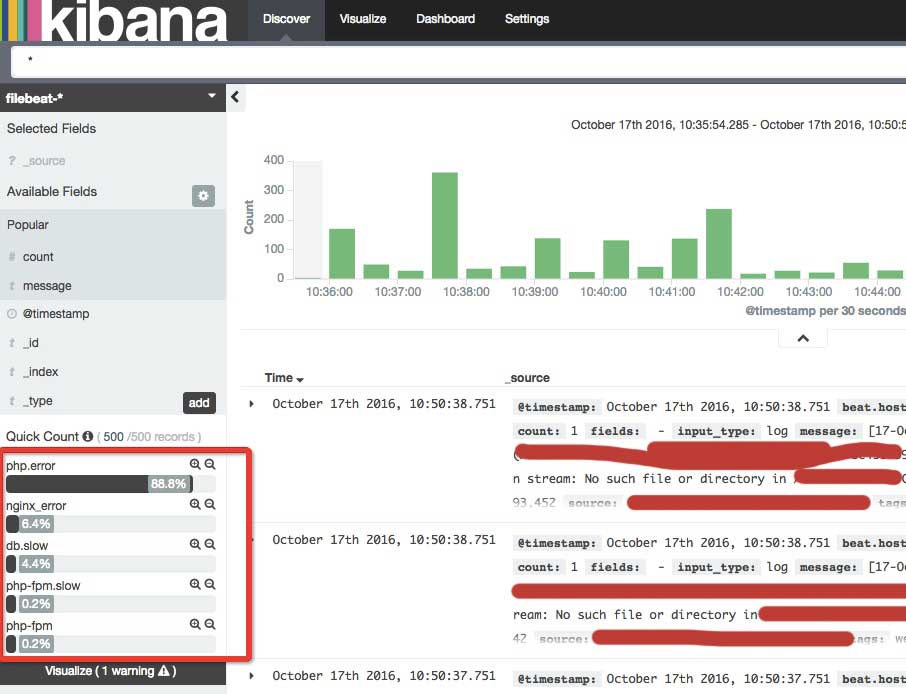
还有更多功能自己发掘把。
4.5 参考资料
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-getting-started.html
https://www.elastic.co/guide/en/kibana/current/getting-started.html
https://www.elastic.co/guide/en/elasticsearch/guide/current/getting-started.html